|
Linqing Zhao(赵林清)
I'm currently a Tenure-track Assistant Professor at the School of Intelligence Engineering and Automation, Beijing University of Posts and Telecommunications (BUPT). Previously, I was a Postdoctoral fellow of Department of Automation, Tsinghua University, affiliated with Intelligent Vision Group (IVG), supervised by Prof. Jiwen Lu.
Email / Google Scholar / Github / 中文主页 |

|
News
|
Recent Selected Publications(*Equal Contribution, #Corresponding Author) |

|
Pseudo Depth Meets Gaussian: A Feed-forward RGB SLAM Baseline
|
|
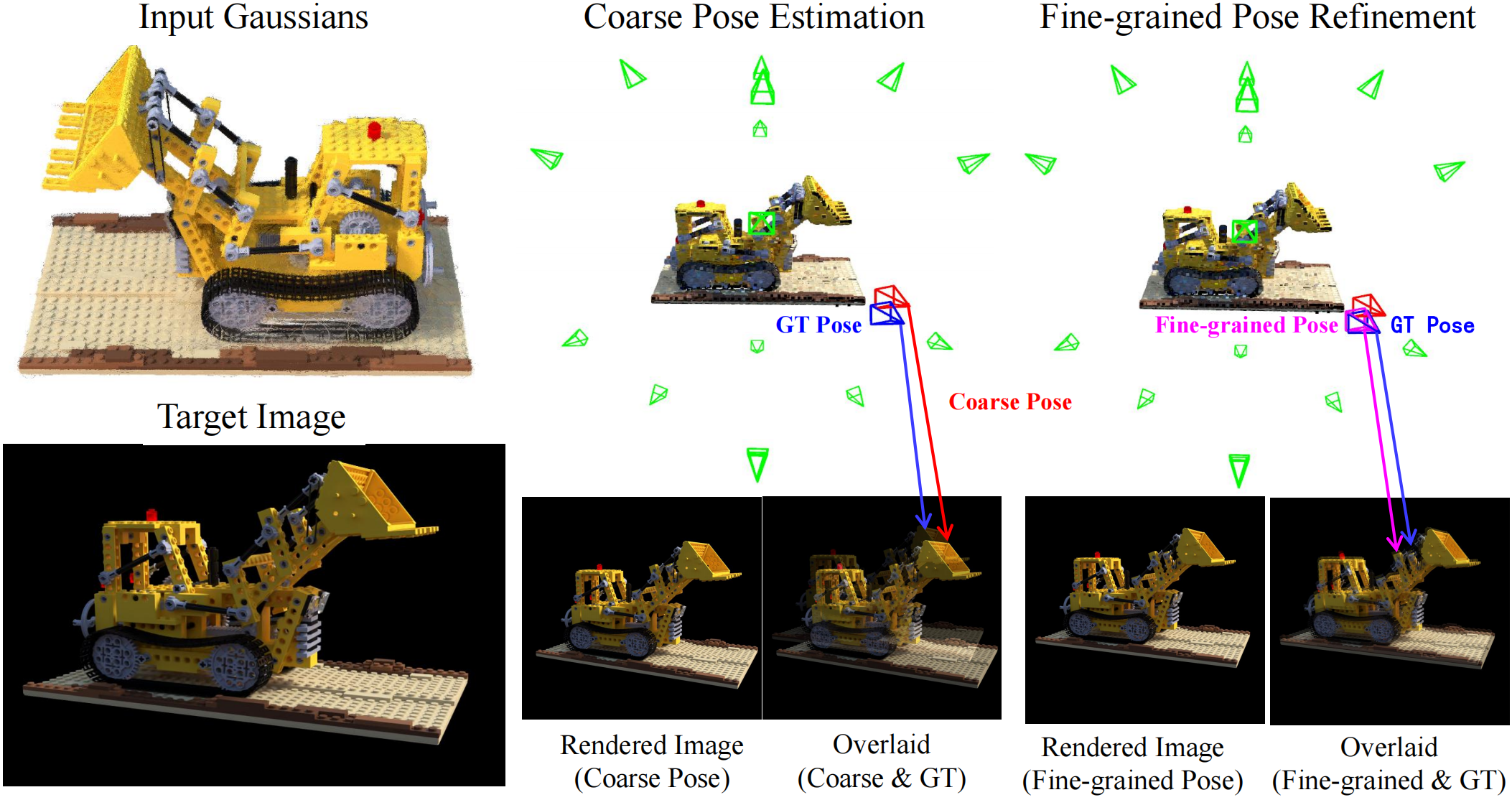
iGaussian: Real-Time Camera Pose Estimation via Feed-Forward 3D Gaussian Splatting Inversion
|
|
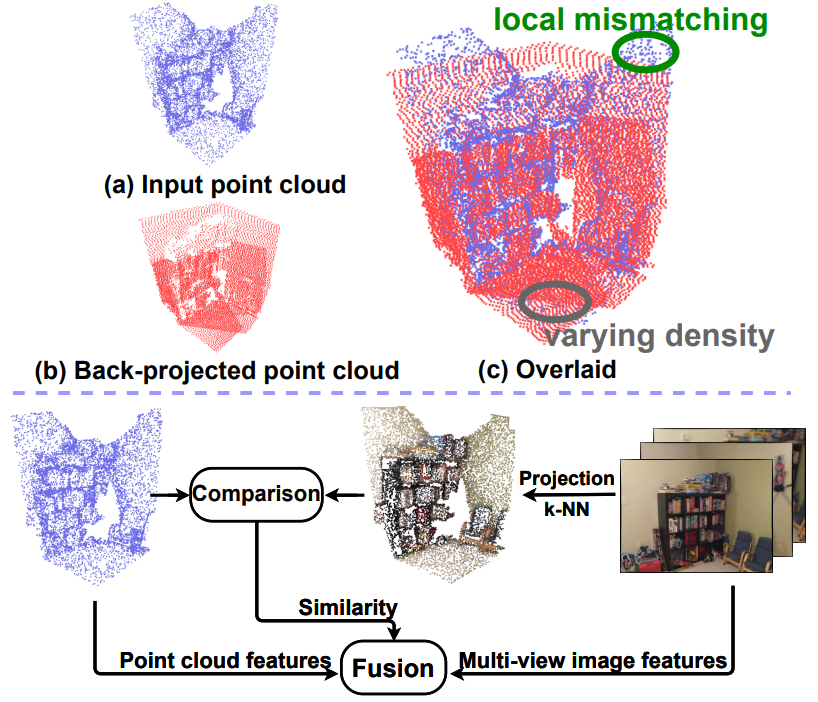
Similarity-Aware Fusion Network for Robust Multi-Modal Semantic Segmentation
|
|
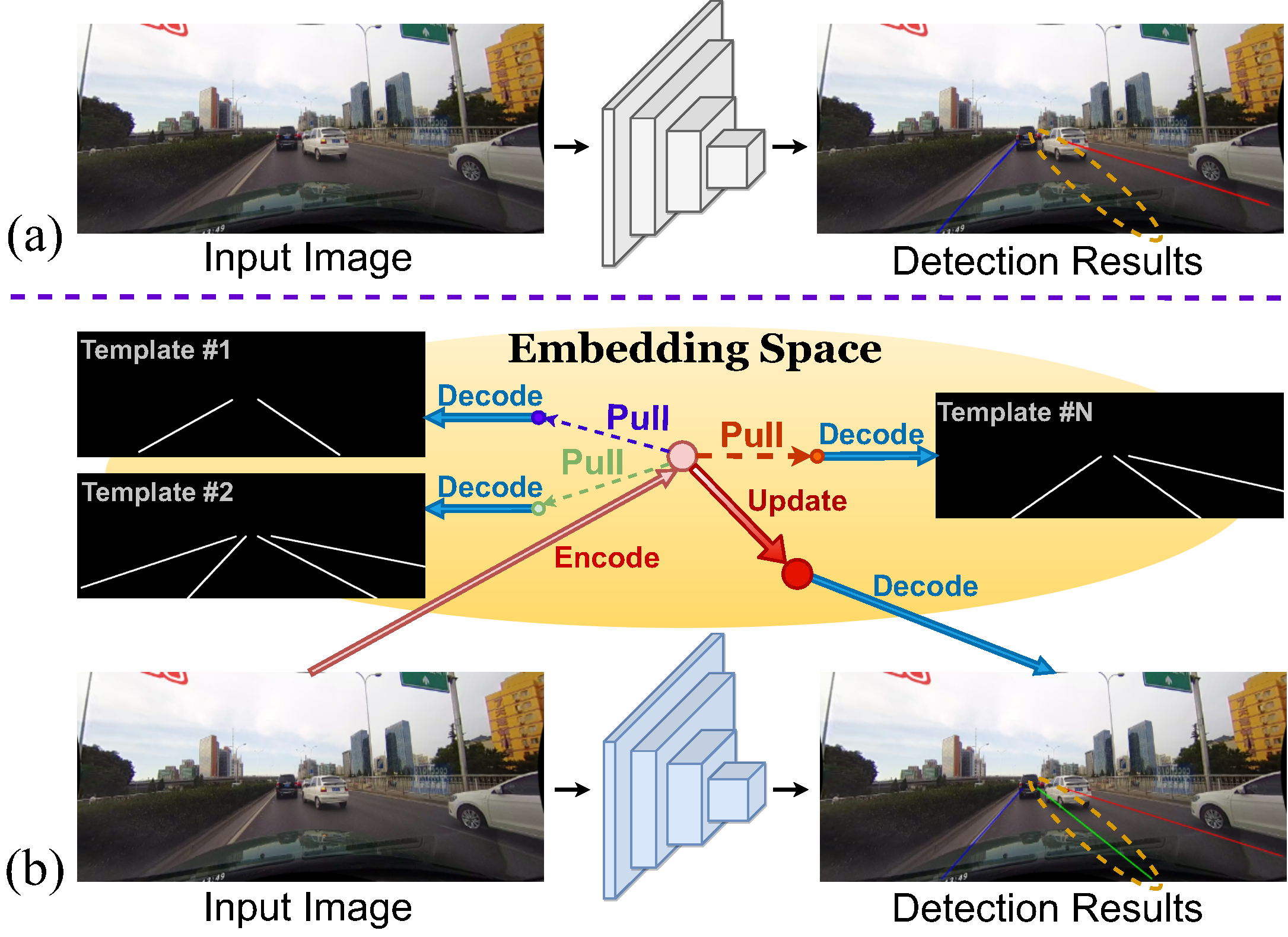
StructLane: Leveraging Structural Relations for Lane Detection
IEEE Transactions on Image Processing (TIP), 2024. We propose the StructLane method to enhance lane detection accuracy and robustness by harnessing the structural relationships among lanes. |
|
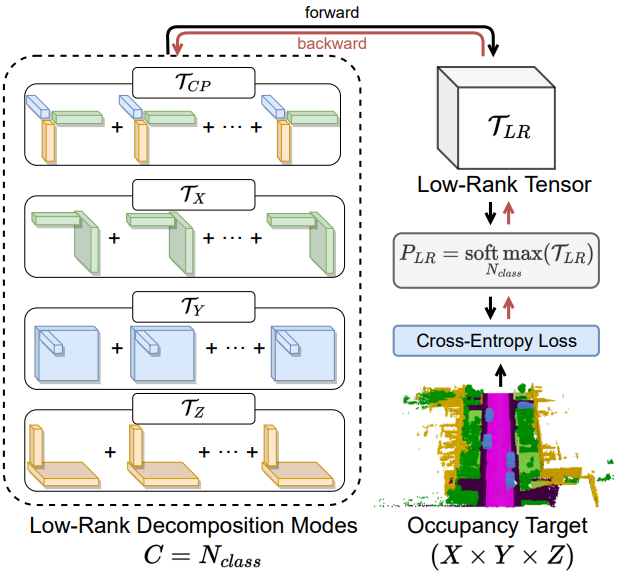
LowRankOcc: Tensor Decomposition and Low-Rank Recovery for Vision-based 3D Semantic Occupancy Prediction
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. We propose LowRankOcc to address spatial redundancy in 3D semantic occupancy prediction, leveraging the inherent low-rank property of occupancy data. |

|
Structure-aware Cross-Modal Transformer for Depth Completion
IEEE Transactions on Image Processing (TIP), 2024. We disentangle the hierarchical 3D scene-level structure from the RGB-D input and construct a pathway to make sharp depth boundaries and object shape outlines accessible to 2D features. |
|
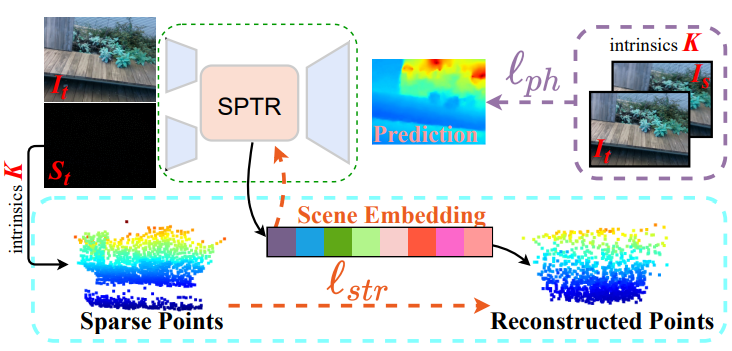
SPTR: Structure-Preserving Transformer for Unsupervised Indoor Depth Completion
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2023. We propose to reformulate depth completion as the process of 3D structure generation, where the generated structure should recover the complete scene and also consist with the known partial structure. |
|
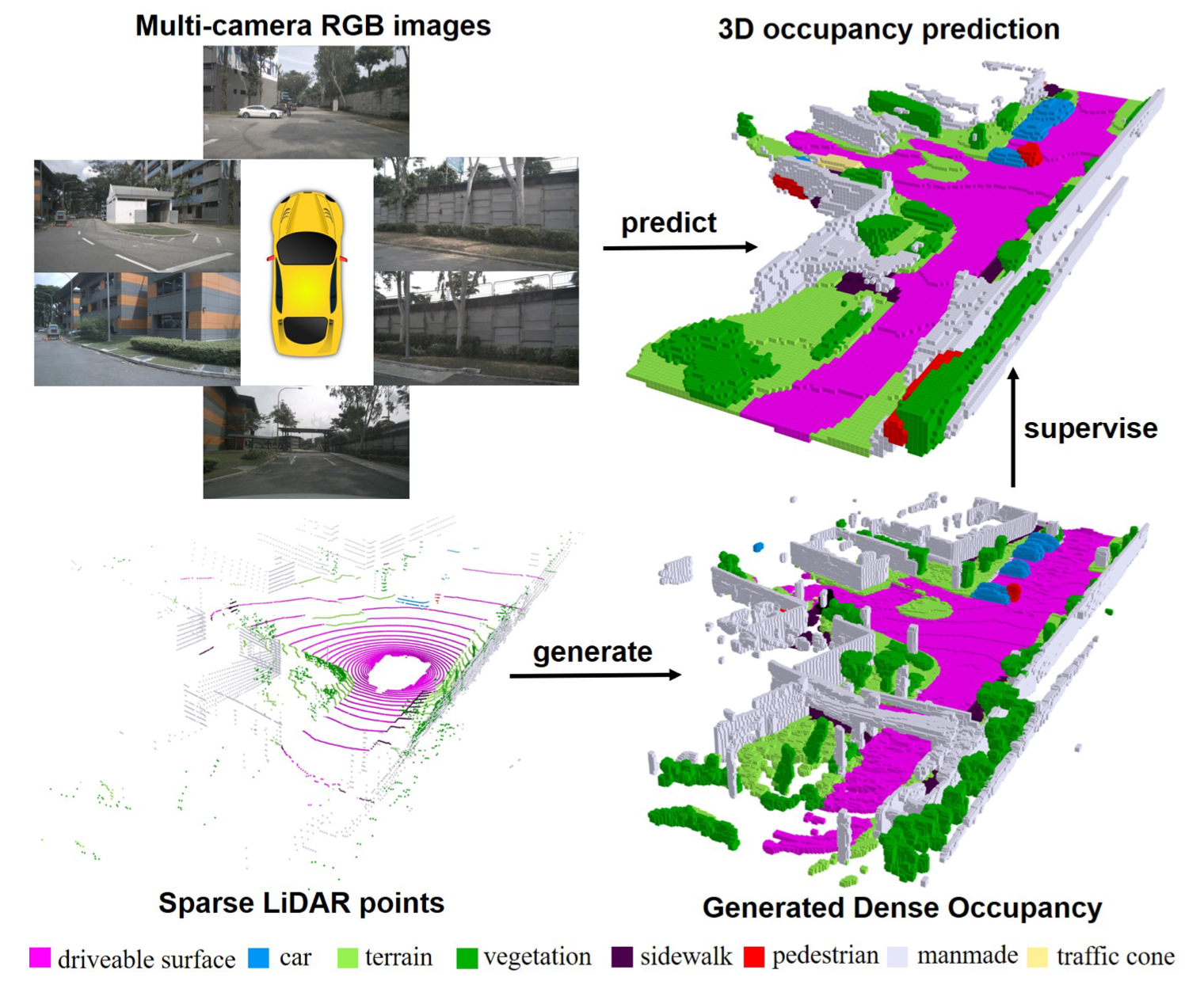
SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving
IEEE International Conference on Computer Vision (ICCV), 2023 We design a pipeline to generate dense occupancy ground truths without expensive occupancy annotations, which enables the training of more dense 3D occupancy prediction models. |

|
Dense Hybrid Proposal Modulation for Lane Detection
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2023. We densely modulate all proposals to generate topologically and spatially high-quality lane predictions with discriminative representations. |

|
SurroundDepth: Entangling Surrounding Views for Self-Supervised Multi-Camera Depth Estimation
Conference on Robot Learning (CoRL), 2022 We propose a SurroundDepth method to incorporate the information from multiple surrounding views to predict depth maps across cameras. |
|
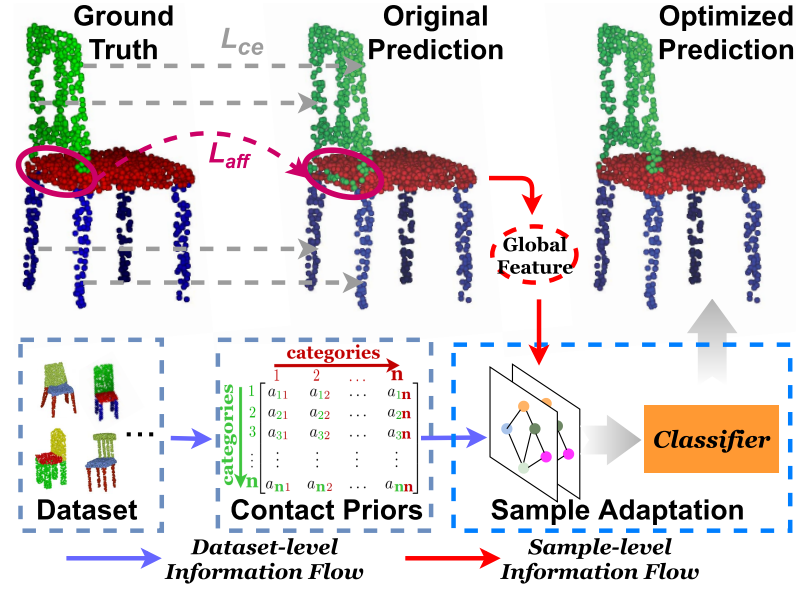
Learning Hybrid Semantic Affinity for Point Cloud Segmentation
|
Programs
|
Honors
|
Academic Services
|
|
|
©